参考 动手学深度学习-11.优化算法
AI辅助创作,部分内容因个人时间精力进行了取舍
梯度下降#
利用泰勒展开,\(f(x+\epsilon) = f(x) + \epsilon f'(x)+O(\epsilon ^ 2)\),由于我们的目的是求得另一个\(x_1\),使得\(f(x_1) \lt f(x)\),其中\(x_1=x+\epsilon\)
换言之就是让$\epsilon f'(x)<0$
固定步长为\(\eta>0\),取\(\epsilon=-\eta f'(x)\),代入可得\(\epsilon f'(x) = -\eta f'(x)^2 <0\)
1
2
3
4
| %matplotlib inline
import numpy as np
import torch
from d2l import torch as d2l
|
定义目标函数为\(f(x)=x^2\),目标函数导数为\(2x\)
1
2
3
4
| def f(x):
return x ** 2
def f_grad(x):
return 2 * x
|
使用\(x=10\)作为初始值,设\(\eta=0.2\),使用梯度下降法迭代\(10\)次
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import matplotlib.pyplot as plt
def gd(eta,f_grad):
x = 10
results = [x]
for i in range(10):
x -= eta * f_grad(x)
results.append(float(x))
print(f'epoch 10,x:{x:f}')
return results
_trace_history = []
def show_trace(results, f, title=None, max_cols=3, reset=False, show=True):
global _trace_history
if reset:
_trace_history = []
_trace_history.append((results, f, title))
if not show:
return
n = len(_trace_history)
cols = min(max_cols, n)
traces = _trace_history[-cols:]
fig, axes = plt.subplots(1, cols, figsize=(4.8 * cols, 3.6))
if cols == 1:
axes = [axes]
for i, (ax, (res, func, t)) in enumerate(zip(axes, traces), start=n - cols + 1):
bound = max(abs(min(res)), abs(max(res)))
f_line = torch.arange(-bound, bound, 0.01)
x_line = f_line.numpy()
y_line = [float(func(x)) for x in f_line]
x_res = [float(x) for x in res]
y_res = [float(func(x)) for x in res]
ax.plot(x_line, y_line, '-')
ax.plot(x_res, y_res, '-o')
ax.set_xlabel('x')
ax.set_ylabel('f(x)')
ax.set_title(t if t is not None else f'第{i}次轨迹')
ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()
results = gd(0.2,f_grad)
show_trace(results, f, title='eta=0.2', reset=True)
|
epoch 10,x:7.295479
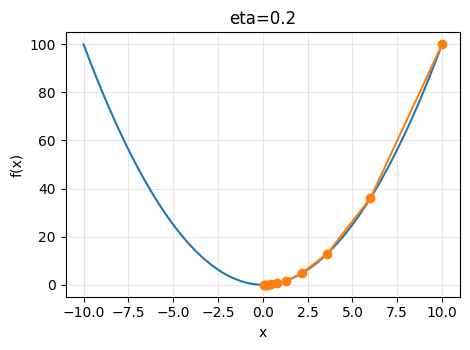
学习率决定目标函数能否收敛到最小值,以及决定收敛速度,学习率过低可能收敛过慢
1
| show_trace(gd(0.05,f_grad), f, title='eta=0.05')
|
epoch 10,x:3.486784

学习率过高可能导致高阶项无法忽视导致发散
1
| show_trace(gd(1.2,f_grad), f, title='eta=1.2')
|
epoch 10,x:289.254655

在非凸函数中,梯度下降并不保证找到全局最小值,它通常会收敛到“离初始点最近”的那个局部最小值或者鞍点
1
2
3
4
5
6
7
8
9
| c = torch.tensor(0.15 * np.pi)
def f(x):
return x * torch.cos(c * x)
def f_grad(x):
return torch.cos(c * x) - c * x * torch.sin(c * x)
show_trace(gd(2,f_grad), f, title='non-convex eta=2', reset=True, show=False)
show_trace(gd(0.2,f_grad), f, title='non-convex eta=0.2')
|
epoch 10,x:-1.528166
epoch 10,x:7.295479

多元梯度下降 \(\pmb{x}\leftarrow \pmb{x}-\eta\nabla f(\pmb{x})\)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| def train_2d(trainer,steps=20,f_grad=None):
x1,x2,s1,s2 = -5,-2,0,0
results = [(x1,x2)]
for i in range(steps):
if f_grad:
x1,x2,s1,s2 = trainer(x1,x2,s1,s2,f_grad)
else:
x1,x2,s1,s2 = trainer(x1,x2,s1,s2)
results.append((x1,x2))
print(f'epoch{i+1}, x1:{float(x1):f}, x2:{float(x2):f}')
return results
_trace2d_pending = []
def _to_float_scalar(v):
if isinstance(v, np.ndarray):
if v.size != 1:
raise ValueError(f'期望标量或长度为1的数组,实际 shape={v.shape}')
return float(v.reshape(-1)[0])
if torch.is_tensor(v):
if v.numel() != 1:
raise ValueError(f'期望标量或长度为1的张量,实际 shape={tuple(v.shape)}')
return float(v.detach().cpu().reshape(-1)[0])
return float(v)
def _eval_surface(func, X1, X2):
try:
Z = func(X1, X2)
if torch.is_tensor(Z):
Z = Z.detach().cpu().numpy()
return np.asarray(Z, dtype=float)
except Exception:
# 兼容仅支持 torch.Tensor 输入的目标函数
X1_t = torch.as_tensor(X1, dtype=torch.float32)
X2_t = torch.as_tensor(X2, dtype=torch.float32)
Z = func(X1_t, X2_t)
if torch.is_tensor(Z):
Z = Z.detach().cpu().numpy()
return np.asarray(Z, dtype=float)
def show_trace_2d(f, results, title='2D optimization trace', show=True, **kwargs):
global _trace2d_pending
if 'show_trace' in kwargs:
show = kwargs.pop('show_trace')
_trace2d_pending.append((f, results, title))
# 延迟显示:先缓存,等下一次 show=True 再统一画图
if not show:
return
traces = _trace2d_pending
n = len(traces)
fig, axes = plt.subplots(1, n, figsize=(6 * n, 5))
if n == 1:
axes = [axes]
for ax, (func, res, t) in zip(axes, traces):
x1_vals_raw, x2_vals_raw = zip(*res)
x1_vals = np.array([_to_float_scalar(x) for x in x1_vals_raw], dtype=float)
x2_vals = np.array([_to_float_scalar(x) for x in x2_vals_raw], dtype=float)
x1_min, x1_max = x1_vals.min(), x1_vals.max()
x2_min, x2_max = x2_vals.min(), x2_vals.max()
pad1 = max(1.0, (x1_max - x1_min) * 0.2)
pad2 = max(1.0, (x2_max - x2_min) * 0.2)
x1_grid = np.linspace(x1_min - pad1, x1_max + pad1, 200)
x2_grid = np.linspace(x2_min - pad2, x2_max + pad2, 200)
X1, X2 = np.meshgrid(x1_grid, x2_grid)
Z = _eval_surface(func, X1, X2)
contours = ax.contour(X1, X2, Z, levels=20, cmap='viridis')
ax.clabel(contours, inline=True, fontsize=8)
ax.plot(x1_vals, x2_vals, '-o', color='tab:red', linewidth=2, markersize=4, label='trajectory')
ax.scatter([x1_vals[0]], [x2_vals[0]], color='tab:blue', s=60, label='start')
ax.scatter([x1_vals[-1]], [x2_vals[-1]], color='tab:green', s=60, label='end')
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_title(t)
ax.legend()
ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()
_trace2d_pending = []
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| def f_2d(x1, x2):
return x1**2 + 2 * x2**2
def gd_2d(x1, x2, s1, s2, f_grad):
eta = 0.1
g1, g2 = f_grad(x1, x2)
return x1 - eta * g1, x2 - eta * g2, 0, 0
def f_2d_grad(x1, x2):
return 2 * x1, 4 * x2
res_2d = train_2d(gd_2d, steps=20, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='GD on f(x1,x2)=x1^2+2x2^2')
|
epoch20, x1:-0.057646, x2:-0.000073

学习率的选取决定学习的效果,一些自适应方法可能不能直接用于深度学习
随机梯度下降#
普通的梯度下降的损失函数是所有样本的和
$$L(\theta) = \sum_{i=1}^{N} L_i(\theta)$$
每次参数更新都需要重新计算\(N\)个样本梯度值和
$$\theta = \theta - \eta \cdot \nabla \left( \sum_{i=1}^{N} L_i(\theta) \right) = \theta - \eta \cdot \sum_{i=1}^{N} \nabla L_i(\theta)$$
当\(N\)的规模过大时,普通梯度下降的时空复杂度可能难以接受
既然计算所有\(N\)个样本太慢,那每次更新时,只随机抽取一小部分样本(甚至只有一个样本)来计算损失函数和估算梯度,会发生什么?
假设我们在每次迭代 \(t\) 时,从全部数据中随机均匀采样一个大小为 \(|B|\) 的子集 \(B_t\)(其中 \(B_t \subset \{1, ..., N\}\))。我们用这个子集的平均梯度来近似整体梯度:
$$\nabla L(\theta) \approx \frac{1}{|B|} \sum_{i \in B_t} \nabla L_i(\theta)$$
此时,参数更新公式变为:
$$\theta = \theta - \eta \cdot \frac{1}{|B|} \sum_{i \in B_t} \nabla L_i(\theta)$$
特别地,当 \(|B|=1\) 时,即每次只随机选一个样本 \(i\),这就是最原始的随机梯度下降(SGD):
$$\theta = \theta - \eta \cdot \nabla L_i(\theta)$$
那用部分估计整体靠谱吗?
$$E\left[ \frac{1}{|B|} \sum_{i \in B_t} \nabla L_i(\theta) \right] =\frac{1}{|B|} \sum_{i \in B_t}E\left[ \nabla L_i(\theta) \right] = \frac{1}{N} \sum_{i=1}^{N} E\left[ \nabla L_i(\theta) \right]= \frac{1}{N} \sum_{i=1}^{N} \nabla L_i(\theta) = \nabla L(\theta)$$
所以说随机梯度是对完整梯度的无偏估计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def sgd(x1,x2,s1,s2,f_grad):
g1,g2 = f_grad(x1,x2)
# 增加随机噪声,实际中只用部分样本计算的梯度自带噪声
g1 += torch.normal(0.0,1,(1,))
g2 += torch.normal(0.0,1,(1,))
eta_t = eta *lr()
return (x1-eta_t*g1,x2-eta_t*g2,0,0)
def constant_lr():
return 1
eta = 0.1
lr = constant_lr
res_2d = train_2d(sgd, steps=50, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='GD on f(x1,x2)=x1^2+2x2^2')
|
epoch50, x1:-0.401927, x2:-0.046643

尽管迭代了\(50\)次,效果看起来不如普通的梯度下降,那么剩下能改变的就是学习率了,固定的学习率无法兼具“启动快(此处不是鸡煲笑话),收敛稳”的效果。
为了解决这个矛盾,我们将学习率从常数 \(\eta\) 变为关于迭代步数 \(t\) 的函数 \(\eta_t\)。
SGD 的更新公式演变为:
$$\theta_{t+1} = \theta_t - \eta_t \cdot \nabla L_i(\theta_t)$$
在实际应用中,我们通常使用以下几种调度方式:
| 策略 | 公式示例 | 特点 |
|---|
| 指数衰减 | \(\eta_t = \eta_0 \cdot \gamma^t\) | 学习率随步数指数级下降,衰减速度快 |
| 分段常数 | 每 30 轮 \(\eta\) 除以 10 | 实现简单,便于手动控制关键阶段的精度 |
| 多项式衰减 | \(\eta_t = \eta_0 \cdot (1 - \frac{t}{T})^k\) | 随训练进度平滑下降,常用于深度学习 |
1
2
3
4
5
6
7
8
9
10
| import math
def exponential_lr():
global t
t += 1
return math.exp(-0.1 * t)
t = 1
lr = exponential_lr
res_2d = train_2d(sgd, steps=50, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='GD on f(x1,x2)=x1^2+2x2^2')
|
epoch50, x1:-0.788887, x2:0.064546

1
2
3
4
5
6
7
8
9
| def polynomial_lr():
global t
t += 1
return (1 + 0.1 * t) ** (-0.5)
t = 1
lr = polynomial_lr
res_2d = train_2d(sgd, steps=50, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='GD on f(x1,x2)=x1^2+2x2^2')
|
epoch50, x1:0.108062, x2:0.041646

随机梯度下降只用一个样本进行更新,这也带来了劣势。首先是向量运算无法充分利用 GPU 的矩阵并行计算能力,其次是单样本梯度估计的方差较大,导致收敛路径震荡剧烈。为解决这两个问题,实际使用时通常用小批量随机梯度下降
单个样本的方差是
$$\text{Var}(\hat{g}) = \text{Var}(g_i) = \sigma^2$$
估计量是 \(m\) 个样本梯度的平均值
$$\hat{g}_{\text{m}} = \frac{1}{m} \sum_{j=1}^{m} g_{i_j}$$
要计算这个平均值的方差,需要利用方差的两个性质,假设样本独立同分布:
- \(\text{Var}(cX) = c^2 \text{Var}(X)\)
- 若 \(X, Y\) 独立,\(\text{Var}(X+Y) = \text{Var}(X) + \text{Var}(Y)\)
推导过程如下:
$$
\begin{aligned}
\text{Var}(\hat{g}_{\text{m}}) &= \text{Var}\left( \frac{1}{m} \sum_{j=1}^{m} g_{i_j} \right) \\
&= \frac{1}{m^2} \text{Var}\left( \sum_{j=1}^{m} g_{i_j} \right) \quad \leftarrow \text{性质 1 } \\
&= \frac{1}{m^2} \sum_{j=1}^{m} \text{Var}(g_{i_j}) \quad \leftarrow \text{性质 2} \\
&= \frac{1}{m^2} \cdot m \cdot \sigma^2 \quad \leftarrow \text{共有 } m \text{ 个项,每项方差为 } \sigma^2 \\
&= \frac{\sigma^2}{m}
\end{aligned}
$$
所以说,当\(m\)增大时,梯度方差是降低的
本节后续内容还请自行阅读书籍啦
SGD看起来已经可以兼顾时间空间,本文结束了!优化算法的时代结…..
真,真的吗?
我们不妨来看下面的情况,使用普通的SGD
$f(x_1,x_2)=0.1x_1^2+10x_2^2$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| def f_2d(x1,x2):
return 0.1*x1**2+10*x2**2
def f_2d_grad(x1, x2):
return 0.2 * x1, 20 * x2
def sgd(x1,x2,s1,s2,f_grad):
g1,g2 = f_grad(x1,x2)
# 增加随机噪声,实际中只用部分样本计算的梯度自带噪声
g1 += torch.normal(0.0,1,(1,))
g2 += torch.normal(0.0,1,(1,))
eta_t = eta *lr()
return (x1-eta_t*g1,x2-eta_t*g2,0,0)
t = 1
eta = 0.1
lr = polynomial_lr
res_2d = train_2d(sgd, steps=100, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
t = 1
eta = 0.1
res_2d = train_2d(sgd, steps=500, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch100, x1:-2.063512, x2:0.006416
epoch500, x1:-0.561228, x2:-0.032223
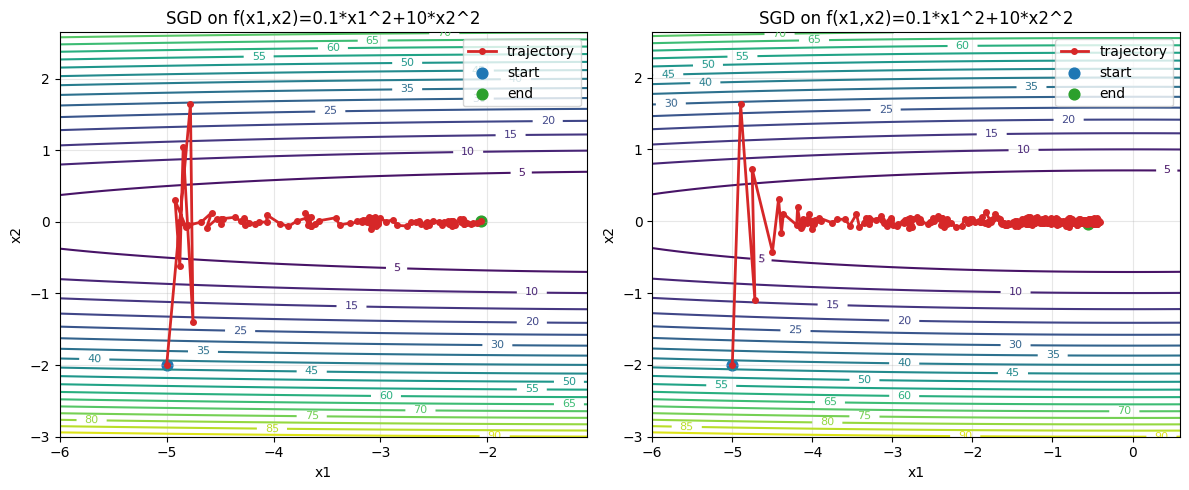
可以看到在“狭长峡谷”上非常缓慢地向右前进,即使提高步数也是杯水车薪。那么如果提高学习率呢?
1
2
3
4
5
6
7
8
9
| t = 1
eta = 0.2
lr = polynomial_lr
res_2d = train_2d(sgd, steps=100, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
t = 1
eta = 0.2
res_2d = train_2d(sgd, steps=500, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch100, x1:-0.517543, x2:0.074684
epoch500, x1:-0.294282, x2:-0.027534
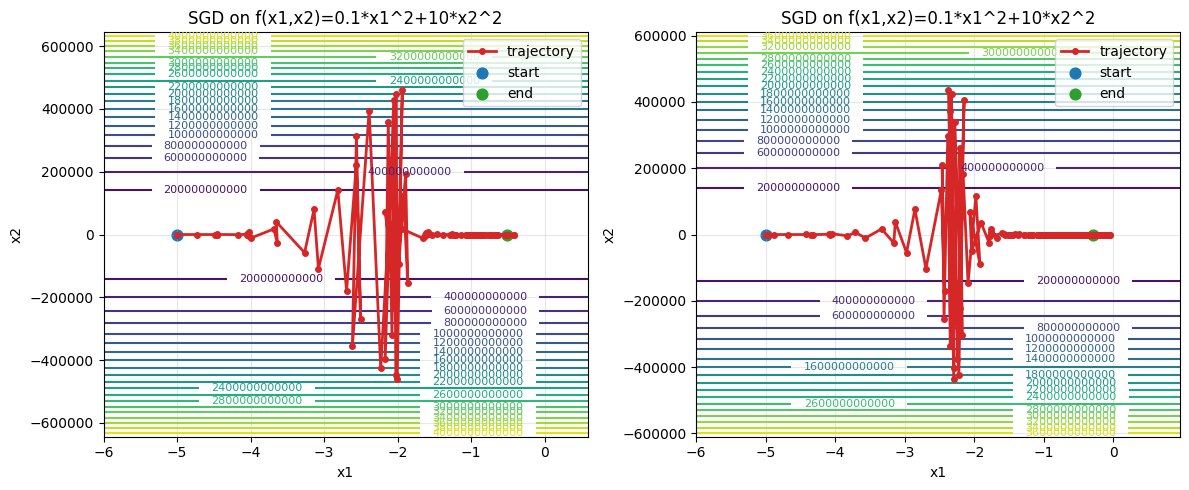
看起来非常恐怖,中间反复横跳,甚至绝对值一度超过了$400000$,或者我们试试更低的学习率
1
2
3
4
5
6
7
8
9
10
11
12
13
| t = 1
eta = 0.02
lr = polynomial_lr
res_2d = train_2d(sgd, steps=100, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
t = 1
eta = 0.02
res_2d = train_2d(sgd, steps=500, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
t = 1
eta = 0.02
res_2d = train_2d(sgd, steps=10000, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch100, x1:-4.278404, x2:0.017078
epoch500, x1:-3.084149, x2:0.006751
epoch10000, x1:-0.454990, x2:-0.000830
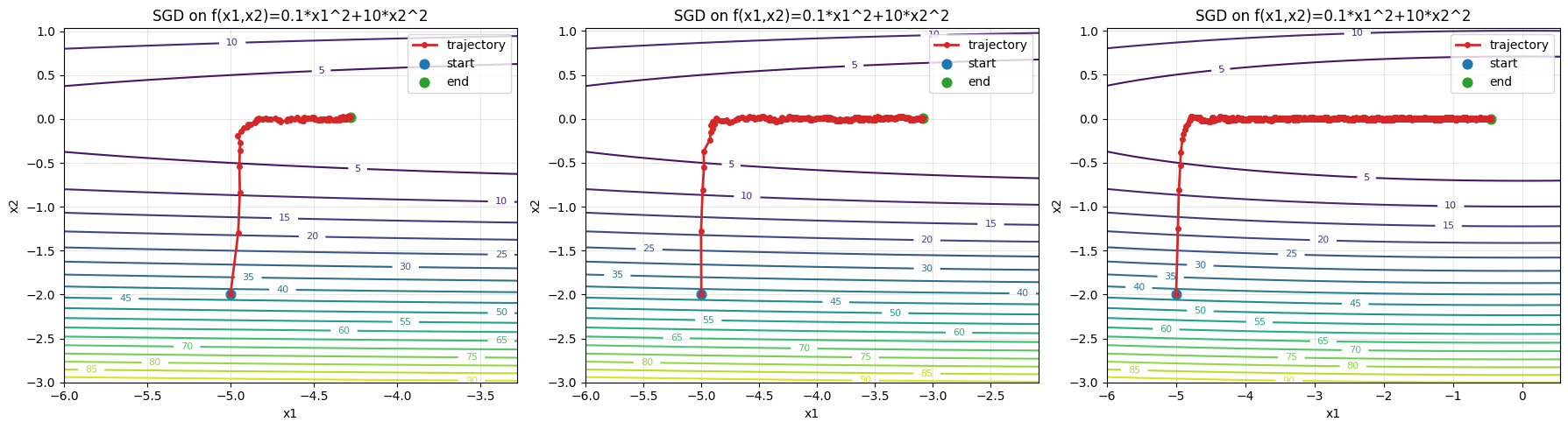
这就是另一种恐怖了,$x_1$跑了$10000$轮还没有慢慢收敛到正确的地方,所以说SGD看起来并不适合这种不同自变量梯度差距较大的情况,那么可能会有疑问,普通GD呢?
1
2
3
4
5
6
7
8
9
| def gd_2d(x1, x2, s1, s2, f_grad):
eta = 0.02
g1, g2 = f_grad(x1, x2)
return x1 - eta * g1, x2 - eta * g2, 0, 0
res_2d = train_2d(gd_2d, steps=50, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='GD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
res_2d = train_2d(gd_2d, steps=5000, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='GD on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch50, x1:-4.092012, x2:-0.000000
epoch5000, x1:-0.000000, x2:-0.000000
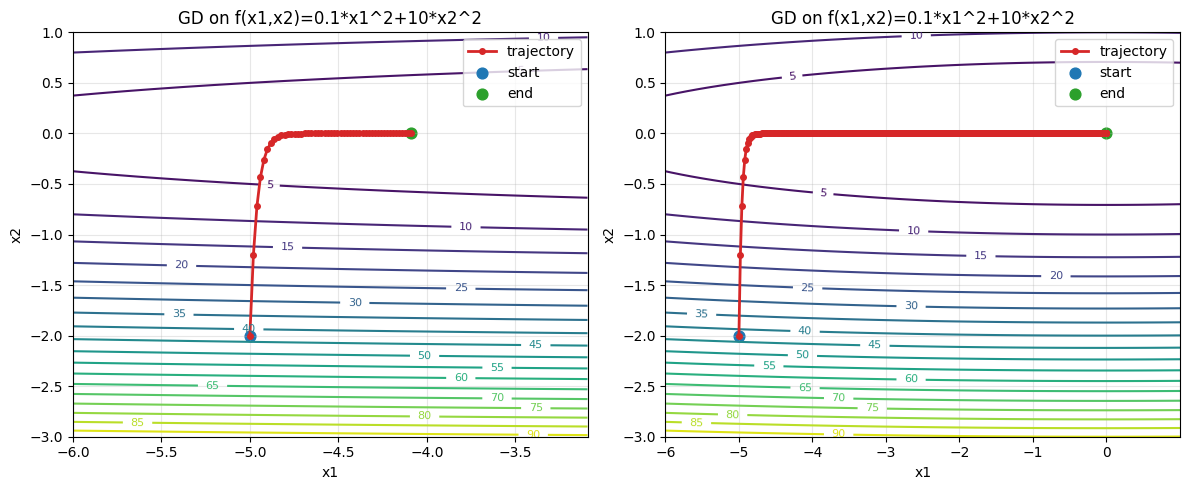
没想到同样的学习率,普通的GD竟然只用了$5000$轮就完成了收敛。还可能存在一种疑问,就是如果SGD换成固定学习率或者是稍微高点的学习率呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| t = 1
eta = 0.02
lr = constant_lr
res_2d = train_2d(sgd, steps=100, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
t = 1
eta = 0.02
res_2d = train_2d(sgd, steps=500, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
t = 1
eta = 0.02
res_2d = train_2d(sgd, steps=10000, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2')
t = 1
eta = 0.05
lr = polynomial_lr
res_2d = train_2d(sgd, steps=100, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
t = 1
eta = 0.05
res_2d = train_2d(sgd, steps=500, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2',show_trace=False)
t = 1
eta = 0.05
res_2d = train_2d(sgd, steps=10000, f_grad=f_2d_grad)
show_trace_2d(f_2d, res_2d, title='SGD on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch100, x1:-3.211442, x2:0.000465
epoch500, x1:-0.571092, x2:0.041077
epoch10000, x1:-0.426865, x2:0.001753
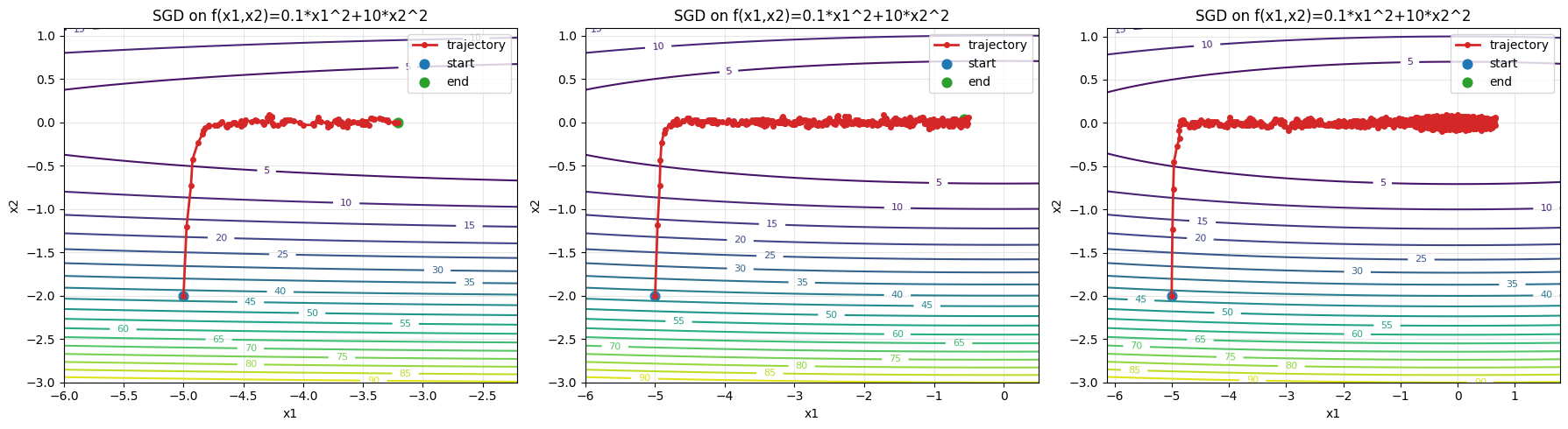
epoch100, x1:-3.305861, x2:-0.013946
epoch500, x1:-1.492732, x2:0.022477
epoch10000, x1:-0.007610, x2:0.010288
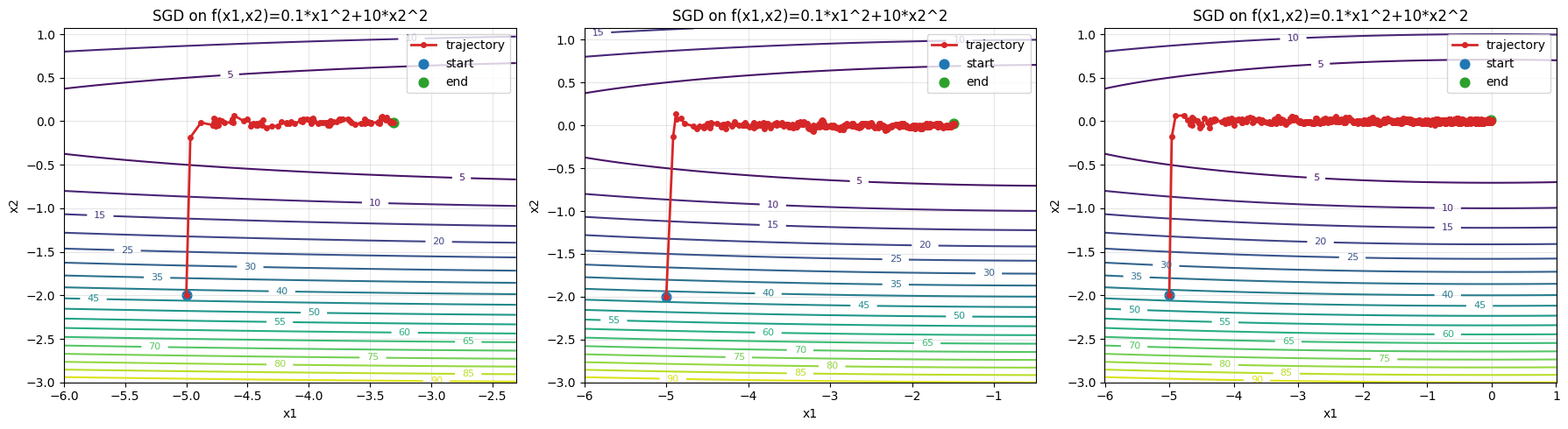
几乎可以确认,SGD在这个问题上速度竟然不如原版GD了,甚至有的时候会跳过正确答案,在两边反复横跳
考虑下这个问题,在$x_1$, $x_2$两个方向上的梯度差距过大,相同学习率的情况下,一个反复横跳,一个慢吞吞走。我们想要的是让反复横跳的慢点,然后慢吞吞的那个快点,换言之就是给走的过快的反复横跳的调低学习率,给走得慢的提高学习率。如何实现呢?
我们要先考虑什么是“反复横跳”,就是梯度发生了进行正负变换,同时学习率与梯度相乘的绝对值是大于当前位置与收敛点的距离的;而“慢吞吞”的则说明梯度正负保持不变,仅仅是梯度较小
考虑到这个性质,很直接就能想到,“横跳”在一些统计学特征与“慢吞吞”的有明显差异,当然,这是后面的部分了。
还可以注意到累加会让横跳的正负抵消掉,同时让慢吞吞的累加变大(我感觉我没法“注意到”)
那么这就是引入下面的方法了:
动量法#
维护另外的量用于累计之前的梯度,这个量被称为动量(momentum) $v$,还可以引入一个$\beta \in [0,1]$来调控历史梯度的影响(怎么感觉有点像某种RNN了)
此时的更新公式如下,其中$g_{t,t-1}$就是用$x_{t-1}计算的梯度$
$$ v_t \leftarrow \beta v_{t-1} + g_{t,t-1} $$
$$ x_t \leftarrow x_{t-1} - \eta v_t$$
接下来试试动量法效果如何吧
1
2
3
4
5
6
7
8
9
10
11
12
| def momentum_2d(x1,x2,v1,v2):
v1 = beta * v1 + 0.2 * x1
v2 = beta * v2 + 20 * x2
return x1 - eta * v1, x2 - eta * v2, v1, v2
eta,beta = 0.1,0.5
res_2d = train_2d(momentum_2d, steps=50)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2',show=False)
res_2d = train_2d(momentum_2d, steps=500)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch50, x1:-0.620000, x2:0.000000
epoch500, x1:-0.000000, x2:-0.000000
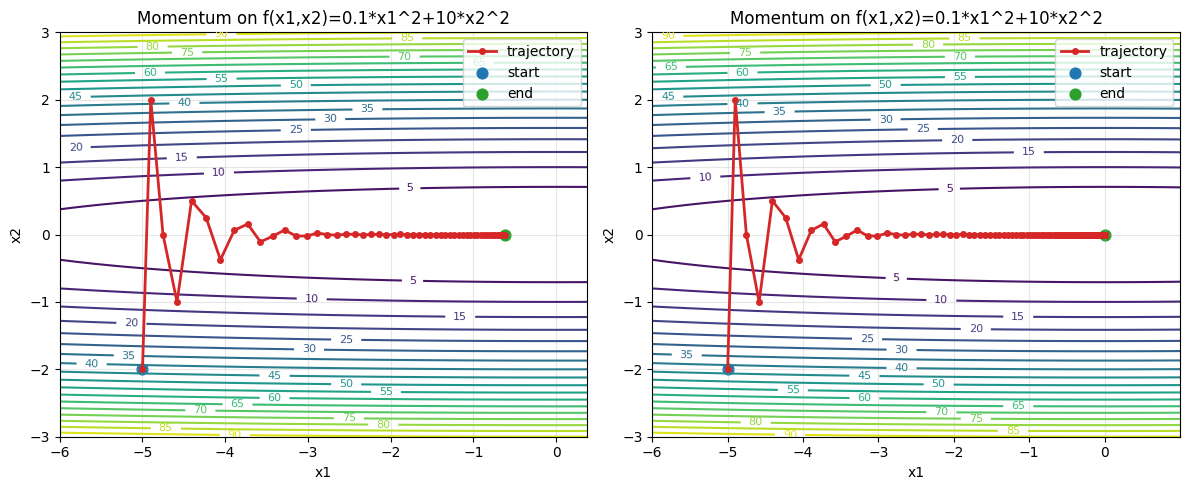
可以看到仅仅需要$500$次,动量法就很好地收敛了。
可以在 Why Momentum Really Works 交互体验效果
$v_t$ 也可以写作 $\sum^{t-1}_{\tau=0} \beta ^{\tau} g_{t-\tau,t-\tau -1} $,也就是说第$i$个梯度对第$j$个梯度的影响是$\beta ^{j-i} g_i$
而 $\sum^{\infty}_{\tau=0} \beta ^{\tau} = \frac{1}{1-\beta}$,所以说动量法会让按照之前学习率的更新步长$\eta v_t$变成$(1-\beta)$倍。所以需要调整新的学习率为$\frac{\eta}{1-\beta}$
本节后续内容还请自行阅读书籍啦
所以说动量法就无敌了吗?
500步似乎还是太多了,能不能让它学习得再快点?
1
2
3
4
5
6
7
8
9
10
11
12
| def momentum_2d(x1,x2,v1,v2):
v1 = beta * v1 + 0.2 * x1
v2 = beta * v2 + 20 * x2
return x1 - eta * v1, x2 - eta * v2, v1, v2
eta,beta = 0.2,0.5
res_2d = train_2d(momentum_2d, steps=50)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2',show=False)
res_2d = train_2d(momentum_2d, steps=500)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch50, x1:-0.054783, x2:-2163401805974677504.000000
epoch500, x1:-0.000000, x2:-296727278529656660666248966637069386465103612668958140152820014382534699916011834206269932680493656464553724555731126971411825227097885375901158837286072555582070825133952718602240.000000
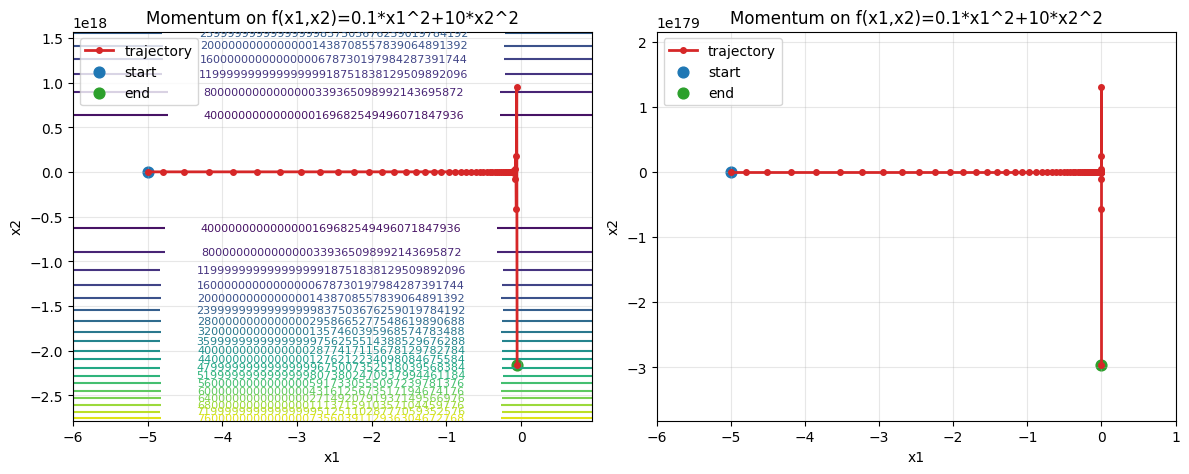
可以看到,我们想让动量法快一点,结果梯度大的那个还是给爆炸了,可能会有人觉得是$\beta$太小了,一般是$0.9-0.99$
那我们再试试
1
2
3
4
5
6
7
8
9
10
11
12
| def momentum_2d(x1,x2,v1,v2):
v1 = beta * v1 + 0.2 * x1
v2 = beta * v2 + 20 * x2
return x1 - eta * v1, x2 - eta * v2, v1, v2
eta,beta = 0.2,0.99
res_2d = train_2d(momentum_2d, steps=50)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2',show=False)
res_2d = train_2d(momentum_2d, steps=500)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch50, x1:3.009175, x2:-14054.174423
epoch500, x1:-0.405540, x2:-7375450158951055580489595224064.000000
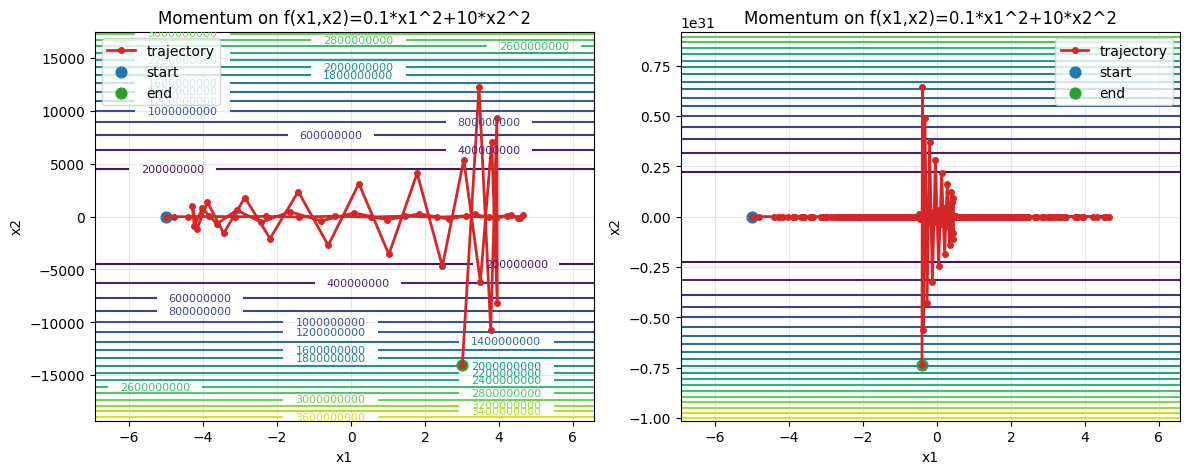
结果依然是爆炸的
详细咨询了LLM,它提出我们的“优化算法”本质是一种时间离散的迭代法,可以利用Jurry依据来判断是否稳定。
LLM计算了目标函数的Hessian矩阵的特征值$\lambda$,其中$g=\lambda x$(来源可能还需要一些补充,这里不写了)
目标函数中$x_1$,$x_2$互不影响,可以单独进行分析。先把$v_t$代入$x_t$的式子消元,得到$x$的二阶递推关系
1.由$x_{t-1}=x_{t-2}-\eta v_{t-1}$得$v_{t-1}=\frac{1}{\eta}(x_{t-2}-x_{t-1})$
2.代入$v_t$,得$v_t = \frac{\beta}{\eta}(x_{t-2}-x_{t-1}) + \lambda x_{t-1} $
3.代入$x_t$更新公式,得到
$$
\begin{aligned}
x_t &= x_t-1 -\eta[\frac{\beta}{\eta}(x_{t-2}-x_{t-1}) + \lambda x_{t-1}] \\
&= x_t-1 -\beta(x_{t-2}-x_{t-1}) -\eta \lambda x_{t-1}\\
&= (1-\eta \lambda+\beta)x_{t-1} -\beta x_{t-2}
\end{aligned}
$$
其特征方程为
$$r^2 - (1-\eta \lambda+\beta) r +\beta=0$$
$|r_1|<1,|r_2|<1$时收敛
然后根据Jurry依据,得到$\eta \lt \frac{2(1+\beta)}{\lambda}$
所以说,当$\beta = 0.99$时,$\eta \lt \frac{2(1+0.99)}{20} = 0.199 $
我们再试试$\eta = 0.198$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def momentum_2d(x1,x2,v1,v2):
v1 = beta * v1 + 0.2 * x1
v2 = beta * v2 + 20 * x2
return x1 - eta * v1, x2 - eta * v2, v1, v2
eta,beta = 0.198,0.99
res_2d = train_2d(momentum_2d, steps=50)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2',show=False)
res_2d = train_2d(momentum_2d, steps=500)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2',show=False)
res_2d = train_2d(momentum_2d, steps=3000)
show_trace_2d(f_2d, res_2d, title='Momentum on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch50, x1:3.131956, x2:-16.857397
epoch500, x1:-0.341571, x2:-2.188185
epoch3000, x1:0.000001, x2:0.000008
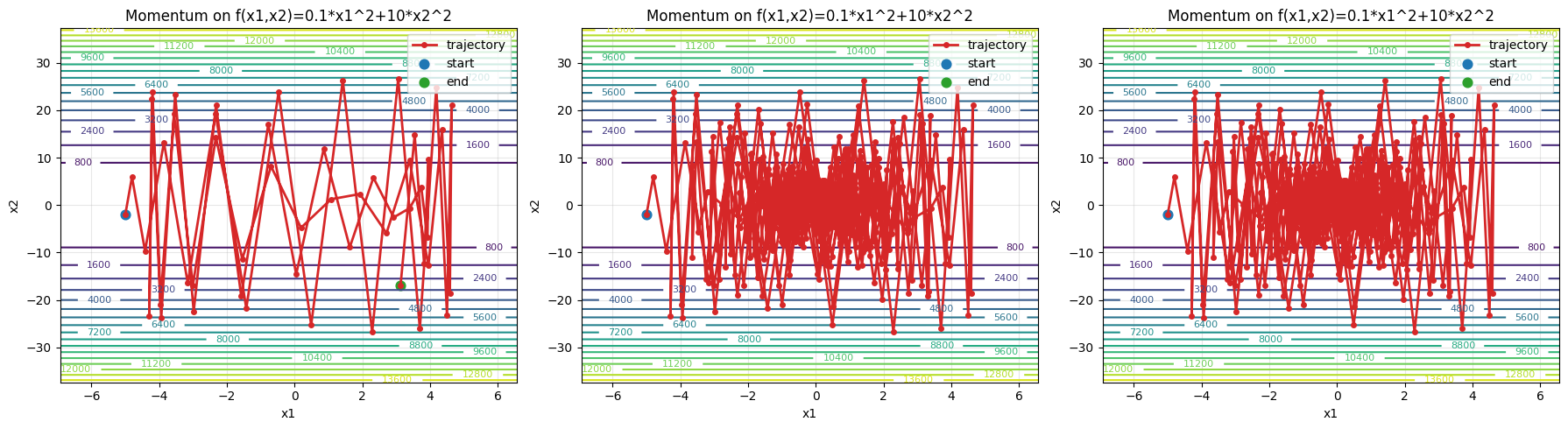
可以看到提高学习率,反而$3000$轮左右才收敛,还不如之前的参数。
那么说明我们这种简单加权累加历史梯度的效果还是有限的,要实现“给走的过快的反复横跳的调低学习率,给走得慢的提高学习率”,需要寻找其他的方法了
就像之前说的,完全可以利用两者某些统计特征的差异,来分配不同的学习率
比较好想的统计特征可能是绝对值之和、平方和、方差之类的
我们来试试绝对值之和的效果会有什么改进吧
与动量法不同,我们是要根据其统计特征对学习率进行缩放,一个可能的方式如下,这里的 $\epsilon$防止除零错误
$$s_t \leftarrow s_{t-1} + |g_t|, \quad x_t \leftarrow x_{t-1} - \frac{\eta}{s_t + \epsilon} g_t$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def abs_2d(x1,x2,s1,s2):
s1 = s1 + abs(0.2 * x1)
s2 = s2 + abs(20 * x2)
return x1 - eta / (s1 + epsilon) * 0.2 * x1,x2 - eta / (s2 + epsilon) * 20 * x2 ,s1,s2
eta,epsilon = 1,1e-6
res_2d = train_2d(abs_2d, steps=50)
show_trace_2d(f_2d, res_2d, title='Abs on f(x1,x2)=0.1*x1^2+10*x2^2',show=False)
res_2d = train_2d(abs_2d, steps=500)
show_trace_2d(f_2d, res_2d, title='Abs on f(x1,x2)=0.1*x1^2+10*x2^2',show=False)
res_2d = train_2d(abs_2d, steps=5000)
show_trace_2d(f_2d, res_2d, title='Abs on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch50, x1:-1.283700, x2:-0.000064
epoch500, x1:-0.165460, x2:-0.000000
epoch5000, x1:-0.000001, x2:-0.000000
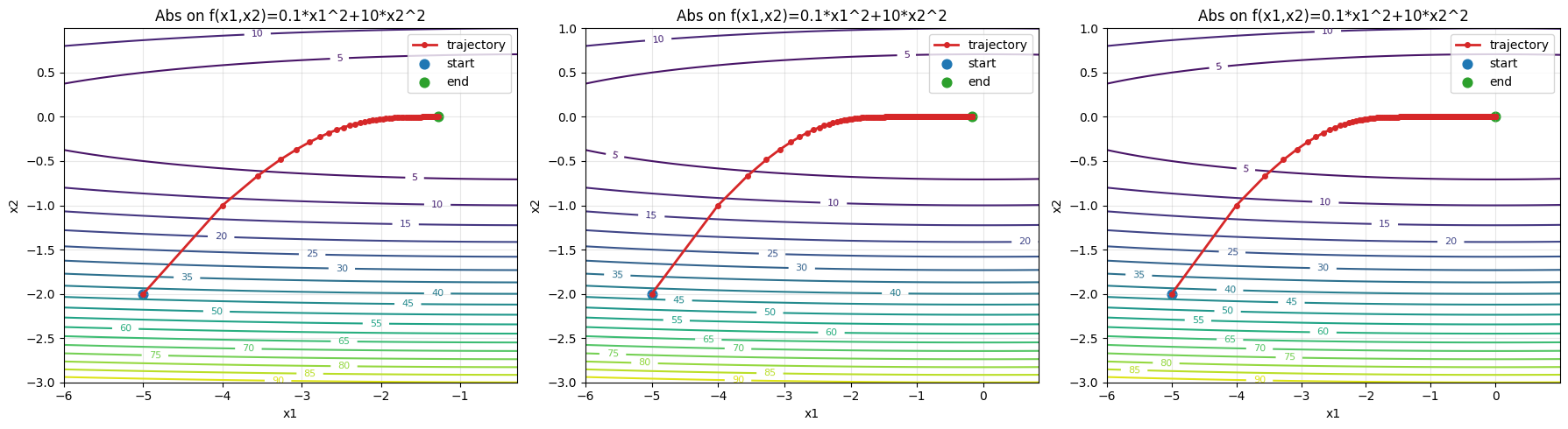
明显稳得多了,不够就是有点太慢了,如果调高学习率呢?
1
2
3
4
5
6
7
8
9
10
11
12
| def abs_2d(x1,x2,s1,s2):
s1 = s1 + abs(0.2 * x1)
s2 = s2 + abs(20 * x2)
return x1 - eta / (s1 + epsilon) * 0.2 * x1,x2 - eta / (s2 + epsilon) * 20 * x2 ,s1,s2
eta,epsilon = 2,1e-6
res_2d = train_2d(abs_2d, steps=50)
show_trace_2d(f_2d, res_2d, title='Abs on f(x1,x2)=0.1*x1^2+10*x2^2',show=False)
res_2d = train_2d(abs_2d, steps=200)
show_trace_2d(f_2d, res_2d, title='Abs on f(x1,x2)=0.1*x1^2+10*x2^2')
|
epoch50, x1:-0.020967, x2:0.000000
epoch200, x1:-0.000000, x2:0.000000
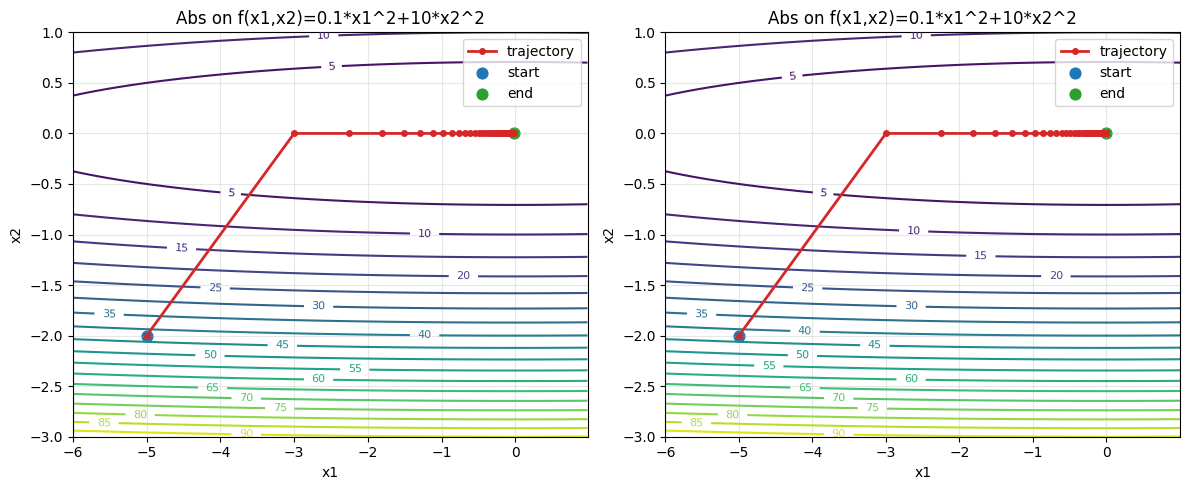
看起来绝对值作为统计历史梯度的方法效果还不错,那为啥人们后来还是抛弃了绝对值呢?
很明显的一个缺点是还是太慢,但本质上的问题我暂时也没有时间精力来考虑了,让我们直接跳到下一个环节,当然建议也是详细阅读原书的该部分,我不太理解,,,
